文档对象模型(Document Object Model,DOM)是一个表达XML文档的标准,大部分Web开发的编程语言都提供了相应的DOM实现。DOM给开发者提供了一种定位XML层级结构的直观方法。
可以把XML的DOM表达方式看作是一颗导航树。一切术语都跟家谱术语(父,子,兄弟)类似。而与家谱的不同之处在于,XML文档从一个独立的根节点(称作文档元素,document element)开始,它包含指向子节点的指针。每个子节点都包含指针指向它的父节点、相邻节点和子节点。
DOM还使用了一些特殊的术语来描述XML树里的对象种类。DOM树中的每个对象都是节点(node)。每个节点都可以有一个类型(type),比如元素、文本或者文档。要进一步学习DOM,必须了解DOM是如何表现和如何定位的。例如:
<p><strong>Hello</strong> how are you doing?</p>
这个片段的每一部分都分解为独立的DOM节点指针,指向其亲戚(父,子,兄弟),使用图谱来表示的话,它应该如下图所示:
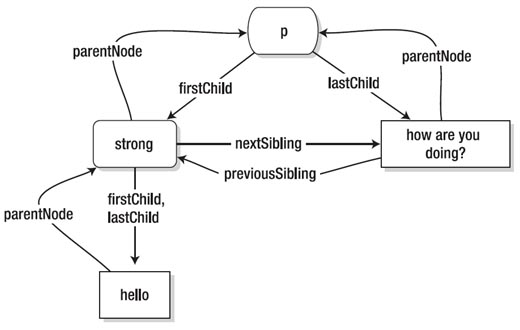
每个独立的DOM节点都包含指向它的相关节点的一系列指针。需要使用这些指针来遍历DOM,所有可用的指针如下图:

通过下面的HTML文档来学习DOM的使用:
<html>
<head>
<title>Introduction to the DOM</title>
</head>
<body>
<h1>Introduction to the DOM</h1>
<p class=”test”>There are a number of reasons why the DOM is awesome, here are some:</p>
<ul>
<li id=”everywhere”>It can be found everywhere.</li>
<li class=”test”>It’s easy to use.</li>
<li class=”test”>It can help you to find what you want, really quickly.</li>
</ul>
</body>
</html>
在这个文档中,根元素是<html>元素,可以通过下面的语句获得:
document.documentElement
根节点同样具有用于定位的指针,使用这些指针就可以浏览整个文档,定位到任何一个元素。比如,要获取<h1>:
document.documentElement.firstChild.nextSibling.firstChild // 试图获取< h1 > 不起作用
DOM指针不仅可以指向元素,也可以指向文本节点,这行代码并会真正指向<h1>元素,而是指向了<title>元素。这是由于空格的原因,在<html>和<head>元素之间有一个行结束符,它被认为是空格,这就意味着第一个节点是文本节点,而不是<head>元素。总结三点:
当试图只使用指针来遍历DOM时,精细编写的HTML标记会产生混乱
仅使用DOM指针来定位文档可能会过于繁琐和不切实际
通常不需要直接存取文本节点,只存取包含文本节点的元素即可
下面的代码用来删除文档中的所有空格,让DOM遍历更容易。但是需要注意的是,这个函数的结果不是持久的,它需要在HTML文档的每一次加载时都重新执行一遍。
function cleanWhitespace( element ) {
// 如果不提供参数,则处理整个HTML文档
element = element || document;
// 使用第一个子节点作为开始指针
var cur = element.firstChild;
// 一直到没有子节点为止
while ( cur != null ) {
// 如果节点是文本节点,且只包含空格
if ( cur.nodeType == 3 && ! /\S/.test(cur.nodeValue) ) {
// 删除这个文本节点
element.removeChild( cur );
// 否则,它就是一个元素节点
} else if ( cur.nodeType == 1 ) {
// 递归整个文档
cleanWhitespace( cur );
}
cur = cur.nextSibling; // 遍历子节点
}
}
如果使用了上面的代码之后再查找<h1>元素后的元素,那么代码应该这样:
cleanWhitespace(); // 查找 < h1 > 元素 document.documentElement .firstChild // 查找 head 元素 .nextSibling // 查找 <body> .firstChild // 得到 h1 元素 .nextSibling // 得到相邻的段落
删除文档中所有空格的代码可以保证遍历DOM文档的稳定性,但明显性能太差了。这个函数使用了节点类型,节点类型可以通过 nodeType 属性来确定,可能会出现的值包括:
元素(nodeType=1):匹配XML文档中的元素,例如<li>、<p>等
文本(nodeType=3):匹配文档中的文本块
文档(nodeType=9):匹配文档的根元素,在HTML文档中是<html>元素
大部分Web开发者不多数情况下仅仅需要遍历DOM元素,可以编写一些辅助函数来达到这个目的,可以取代标准的previousSibling、nextSibling、firstChild、lastChild和parentNode。
查找相关元素的前一个兄弟元素的函数
function prev( elem ) {
do {
elem = elem.previousSibling;
} while ( elem && elem.nodeType != 1 );
return elem;
}
查找相关元素的下一个兄弟元素的函数
function next( elem ) {
do {
elem = elem.nextSibling;
} while ( elem && elem.nodeType != 1 );
return elem;
}
查找元素第一个子元素的函数
function first( elem ) {
elem = elem.firstChild;
return elem && elem.nodeType != 1 ?
nextSibling( elem ) : elem;
}
查找元素最后一个子元素的函数
function last( elem ) {
elem = elem.lastChild;
return elem && elem.nodeType != 1 ?
prevSibling( elem ) : elem;
}
查找元素父元素的函数
function parent( elem, num ) {
num = num || 1;
for ( var i = 0; i < num; i++ )
if ( elem != null ) elem = elem.parentNode;
return elem;
}
[/code]
如果要查找<h1>元素的下一个元素,可以这样:
// 查找 < h1 > 元素的下一个元素
next( first( document.body ) )
转载请注明:陈童的博客 » JavaScript的语言特性 — DOM



