元数据
元数据(MetaData),关于数据的数据或者叫做用来描述数据的数据,或者叫做信息的信息。我们可以把元数据简单的理解成,最小的数据单位。元数据可以为数据说明其元素或属性(名称、大小、数据类型等),或其结构(长度、字段、数据列),或其相关数据(位于何处、如何联系、拥有者)。
举几个简单的例子:
1. 使用数码相机拍摄的数码照片都会存在一个EXIF信息。它就是一种用来描述数码图片的元数据。根据EXIF标准,这些元数据包括:Image Description(图像描述、来源. 指生成图像的工具 )、Artist(作者)、Make( 生产者)、Model (型号)、….、等等。
2. 很多网站都用到HTML的<meta>标记,这里面包含的关键词不会出现在网页界面中,但搜索引擎可以用它描述网站:
<meta name=”keywords” content=”information architecture, content management,knowledge management, user experience”>
元数据可以分为以下三类:
结构化元数据:与事物构成有关的元数据。描述信息的等级,将离散的数据组织成结构化的信息。
管理性元数据:与事物处理方式有关的元数据。描述一类信息的属性,帮助信息通过相同属性进行划分。
描述性元数据:与事物本质有关的元数据。说明数据的创建者及生命周期等用户管理的属性。
元数据对信息架构的意义
元数据是一种很有效的方法,是为产品的可查找性服务的,用以确保网站上各种形式的内容确实都能被查找到。用户在查找信息的时候不会按照机器思维去找(不会输入该照片的ID),而是直接输入关于信息的描述性信息如:“平板电脑、圣诞卡”。也就意味着在创建关于描述性元数据的时候要尽量的提取出关于这个对象所讲述的故事,这些才是人们能记住的和习惯搜索的细节。
受控词表
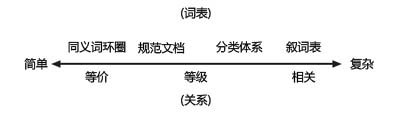
受控词表是一份等价术语(equivalent terms)清单,按同义词环圈(synonym ring)的形式排列。
或者是一份优选术语(preferred terms)清单,储存在规范文档(authority file)中。
定义术语之间的等级关系(上位类——broader、下位类——narrower)就有了分类体系(classification scheme)。下图说明了这几种不同受控词表的关系:
同义词环圈(Synonym Rings)
把一组定义为等价关系的词汇连接起来,以供搜索之用。将具有相同含义的元数据描述信息放到一起,在搜索的时候首先匹配全字符,然后再匹配相关同义词,这样可以提高搜索的查全率,也是模糊搜索的一个特性。如下图所示:
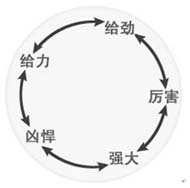
同义词环圈主要解决的问题是:当挖掘网站日志或者做关键词分析的时候,就会发现不同的人在寻找同样的内容时,会输入不同的术语。同义词环圈就是要覆盖这些用户可能输入的同义词。
20世纪80年代Bellcore所做的研究中发现:同义词环圈可以大幅提高查全率,同时也会降低查准率。解决办法是规定精确匹配的关键词结果要放在搜索结果清单的顶端。或者最初的搜索可以忽略同义词环圈,但是提供选项在结果稀少或者无结果时,扩展搜索包含相关术语。
规范文档(Authority Files)
一份优选术语或可接受值的清单,不含词形变化或同义词。
规范文档定义术语的基本范围,主要包含优选术语,即定义出来的最高层级的叙词表,其他异形术语或同义词可以从规范文档中进行扩展,这就使选择限定在一定的范围之内,对于大型系统,要保证一致性,必须提高规范的作用。下图是个规范文档的示例:
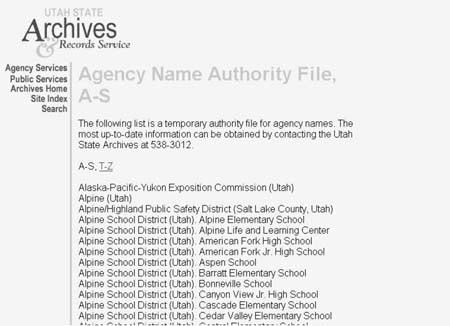
事实上,规范文档通常包含优选术语(preferred terms)和异形术语(variant terms)。换句话说,规范文档也是同义词环圈,其中包括优选术语或可接受的值。例如:美国各州有标准简写,规范文档中只包含可接受的代码:
AL, AK, AZ, AR, CA, CO, CT, DE, DC, FL, GA, HI, ID,
IL, IN, IA, KS, KY, LA, ME, MD, MA, MI, MN, MS, MO, MT, NE, NV, NH,
NJ, NM, NY, NC, ND, OH, OK, OR, PA, PR, RI, SC, SD, TN, TX, UT, VT,
VA, WA, WV, WI, WY.
然而,为了让这份清单可以应用在在大部分场合里,则至少还需要包括各州完整州名的对照表:
AL Alabama
AK Alaska
AZ Arizona
AR Arkansas
CA California
CO Colorado
CT Connecticut
. . .
为了满足更多的应用场合,也可以包含各州州名的各种不同称呼:
CT Connecticut, Conn, Conneticut, Constitution State
分类体系(Classification Schemes)
所谓分类体系指的就是优选术语的等级式排法,例如杜邦十进制分类法。最近很多人喜欢用分类法(Taxonomy)这个词。
在优选术语中也需要进行等级的分类,否则数量多了以后对于信息检索会成倍的复杂。而涉及分类,则会有各种各样的方式,其中的杜邦十进制分类法则是在图书馆中应用最广泛的方法。杜邦十进制分类法(Dewey Decimal Classification,DDC)诞生于1876年,是世界上使用最广泛的分类系统。杜邦十进制分类法最简单的形式是一个等级式的清单,由10个顶级分类开始,再逐一向下延伸细节:
000 计算机科学、资讯与总类(Computers, information, & general reference)
100 哲学与心理学(Philosophy & psychology)
200 宗教(Religion)
300 社会科学(Social sciences)
400 语言(Language)
500 自然科学(Science)
600 技术应用科学(Technology)
700 艺术与休闲(Arts & recreation)
800 文学(Literature)
900 历史、地理与传记(History & geography)
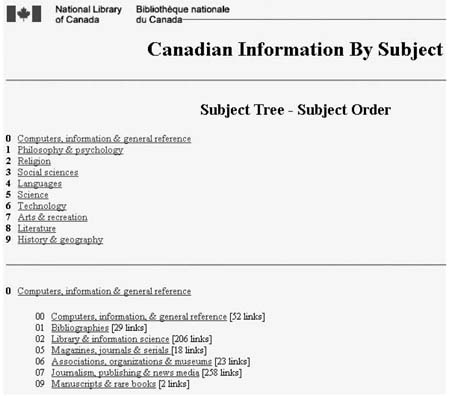
下图是加拿大国家图书馆使用DDC作为一个可浏览的登记系统:
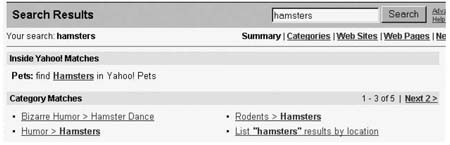
DDC在网站分类搜索也经常出现,下图是在Yahoo!的搜索结果中显示“Category Matches”,这样可以强化用户对Yahoo!分类体系的熟悉度:
叙词表(Thesauri)
叙词表的重要目标是同义词管理,把许多同义词或异形术语对应到某个优选术语或概念上。建立3种基本类型的语义关系模型:
1. 等价关系:同义词管理
2. 等级关系:把优选术语分类成类别和子类别
3. 相关关系:建立有意义的连接,而这种有意义的连接并非由等级关系或等价关系来处理
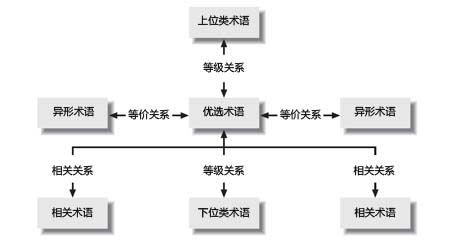
下图显示了每个优选术语都是其自身语义网络的中心。
技术行话(Technical Lingo)
□ 优选术语(Preferred Term,PT):可接受术语、可接受值、标题词、或者描述语。是所有关系的基础。例如对学校的描述中,“哈尔滨工业大学”是标准的表达方式。它就是我们学校的优选词语
□ 异形术语(Variant Term,VT): 入口词或非优选术语。与优选术语定义等价。例如“哈尔滨工业大学”又称为“哈工大”
□ 上位类术语(Broader Term,BT):优选术语的上层术语,术语等级中的较高一层。比如“哈尔滨工业大学”这个词汇的上位类术语可能是“高等院校”、“大学”等词汇
□ 下位类术语(Narrower Term,NT):优选术语的子术语,处于等级中较低的一层。相对“哈尔滨工业大学”,它的下位类术语可能是“航天”、“工科”等词汇
□ 相关术语(Related Term,RT):通过相关关系与优选术语关联,用以表达词汇间的“强烈暗示”关系。例如“哈尔滨工业大学”这个词汇,可能强烈的暗示着“部属院校”,“985工程”等词汇
□ 用(Use,U):叙词表使用的语法,A 用 B
□ 代(Used For,UF):叙词表使用的语法 A 代 B
□ 范围注释(Scope Note,SN):优选术语定义的特定类型,用来限定术语的定义,尽可能消除模糊性
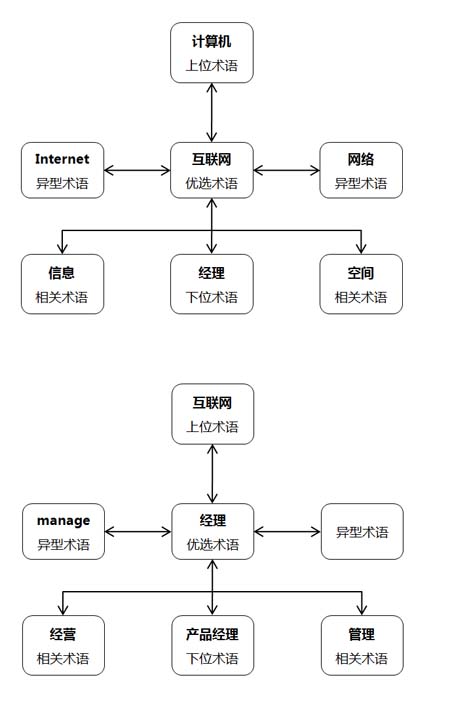
叙词表实例
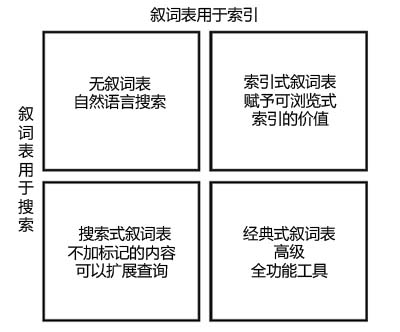
叙词表的种类
1. 经典式叙词表——按照我们上面描写的步骤,完整创建形成的叙词表,是一种全方位的叙词表
2. 索引式叙词表——信息结构相对固定,用户也相对固定,没有能力提供引擎级搜索,只能将受控词表拿出来做一个索引让用户进行浏览式查找
3. 搜索式叙词表——面向大众的信息系统,信息更新很快或者用户群不固定,无法建立相对固定的索引,在搜索时匹配受控词表,在应用叙词表的3种关系时权衡查准率和查全率,并通过搜索界面的设计,提供更加灵活的浏览方式
转载请注明:陈童的博客 » 叙词表、受控词表以及元数据——概念解释